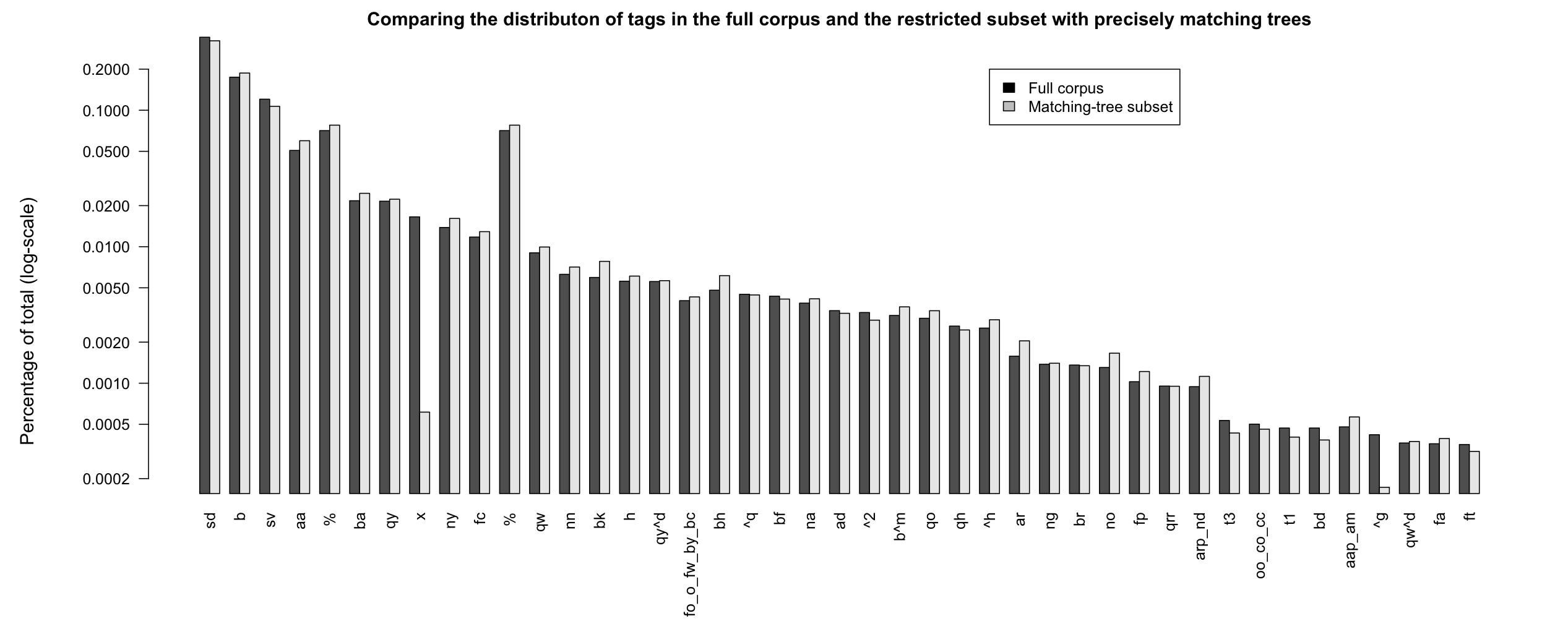
Figure PERCOMPARE
Comparing percentages of tags for the full corpus and the
restricted subset that have single, precisely matching trees.
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2, with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
Recommended reading:
Note: Here is updated SwDA code that is Python 2/3 compatible. It is recommended over the code below.
Code and data:
The SDA trascripts are a free download:
The files are human-readable text files with lines like this:
b B.22 utt1: Uh-huh. /
sd A.23 utt1: I work off and on just temporarily and usually find friends to babysit, /
sd A.23 utt2: {C but } I don't envy anybody who's in that <laughter> situation to find day care. /
b B.24 utt1: Yeah. /
It's worth unpacking the archive file and opening up a few of the transcripts to get a feel for what they are like.
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to align the two resources Calhoun et al. 2010, §2.4. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the conversations and their participants. I'd like us to have easy access to all this information, so I created a version of the corpus that pools all of this information to the best of my ability:
When you unpack swda.zip, you get a directory with the same basic structure as that of swb1_dialogact_annot.tar.gz. The file swda-metadata.csv contains the transcript and caller metadata for this subset of the Switchboard.
The format for all the transcript files is the same. I describe the column values below, in the context of the Python code I wrote for us to work with this corpus.
The Python classes:
The code's Transcript objects model the individual files in the corpus. A Transcript object is built from a transcript filename and the corpus metadata file:
Transcript objects have the following attributes:
| Attribute name | Object type | Value |
|---|---|---|
| ptb_basename | str | The filename: directory/basename |
| conversation_no | int | The numerical conversation Id. |
| talk_day | datetime | with methods like month, year, ... |
| topic_description | str | short description |
| length | int | in seconds |
| prompt | str | long decription/query/instruction |
| from_caller_no | int | The numerical Id of the from (A) caller |
| from_caller_sex | str | MALE, FEMALE |
| from_caller_education | int | 0, 1, 2, 3, 9 |
| from_caller_birth_year | datetime | YYYY |
| from_caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| to_caller_no | int | The numerical Id of the to (B) caller |
| to_caller_sex | str | MALE, FEMALE |
| to_caller_education | int | 0, 1, 2, 3, 9 |
| to_caller_birth_year | datetime | YYYY |
| to_caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| utterances | list | A list of Utterance objects. |
The attributes permit easy access to the properties of transcripts. Continuing the above:
The utterances attribute of Transcript objects is the list of Utterance objects for that corpus, in the order in which they appear in the original transcripts.
Utterance objects have the following attributes:
| Attribute | Object type | Value |
|---|---|---|
| caller | str | A, B, @A, @B, @@A, @@B |
| caller_no | int | The caller Id. |
| caller_sex | str | MALE or FEMALE |
| caller_education | str | 0, 1, 2, 3, 9 |
| caller_birth_year | int | 4-digit year |
| caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| transcript_index | int | line number relative to the whole transcript |
| utterance_index | int | Utterance number (can span multiple TranscriptIndex numbers) |
| subutterance_Index | int | Utterances can be broken across line. This gives the internal position. |
| tag | list | strings; see below |
| text | str | the text of the utterance |
| pos | str | the part-of-speech tagged portion of the utterance |
| trees | nltk.tree.Tree | the parse of Text; see below for discussion |
Assuming you still have your Python interpreter open and the trans instance set as before, you can continue with code like the following:
Perhaps the most noteworthy attribute is utt.trees. This is always a set of nltk.tree.Tree objects (sometimes an empty set, because only a subset of the Switchboard was parsed). For our utt instance, there is just one tree, and it properly contains the actual utterance content. In this case, the rest of the tree occurs two lines later, because speaker A interrupts:
Cautionary note: Because the trees often properly contain the utterance, they cannot be used to gather word- or phrase-level statistics unless care is taken to restrict attention to the subtrees, or fragments thereof, that represent the utterance itself. For additional discussion, see the Penn Discourse Treebank 3 Trees section below.
The main interface provided by swda.py is the CorpusReader, which allows you to iterate through the entire corpus, gathering information as you go. CorpusReader objects are built from just the root of the directory containing your csv files. (It assumes that swda-metadata.csv is in the first directory below that root.)
The two central methods for CorpusReader objects are iter_transcripts() and iter_utterances().
Here's a function that uses iter_transcripts() to gather information relating education levels and dialect areas:
The method iter_utterances() is basically an abbreviation of the following nested loop:
The following code uses iter_utterances() to drill right down to the utterances to count the raw tags:
The output is a list that is very much like the one under "Finally, for reference, here are the original 226 tags" at the Coders' Manual page. (I don't know why the counts differ slightly from the ones given there. I tried many variations — adding/removing * or @ from the tags; adding/removing a hard-to-detect nameless file in the distribution repeating sw09utt/sw_0904_2767.utt, etc., but I was never able to reproduce the counts exactly.)
It is possible to work with our SwDA CSV-based distribution using a program like Excel or R. The following code shows how to read in the CSV files and work with them a bit in R:
We can also read in the metadata and relate an utterance to it via the conversation_no value:
In principle, this could be every bit as useful as the Python classes. Indeed, there are advantages to working with data in tabular/database format, as opposed to constantly looping through all the files. However, if you take this route, you'll have to write your own methods for dealing with the special values for trees, tags, dates, and so forth. I think Python is ultimately a better tool for grappling with the diverse information in the SwDA.
I now briefly review the special annotations of this subset of the Switchboard: the act tags, the POS annotations, and the parsetrees.
There are over 200 tags in the corpus. The Coders' Manual defines a system for collapsing them down to 44 tags. (They say 42; I am not sure what they do with 'x', and their table has 43 rows, so it might be that 42 is just a minor miscount.)
The Utterance object method damsl_act_tag() converts the original tags to this 44 member subset:
The tags are the main addition to the corpus. Here is the table of training-set stats from the Coders' Manual extended with a column giving the total counts for the entire corpus, using damsl_act_tag().
If you could provide more context or clarify your question, I'd be happy to try and offer more specific guidance or information.
Title: "The Social Experiment: What Happens When 29 Guys Share a Wife at a Party?"
Feature Description:
In a bold social experiment, 30 men and one woman came together at a party to explore the dynamics of a shared relationship. The woman, who we'll call "The Wife," was the central figure, while the 29 men took on the role of "co-husbands." The goal was to observe how this unconventional arrangement would play out in a controlled environment.
The Experiment:
Key Takeaways:
The Outcome:
The experiment concluded with some surprising and thought-provoking results. The Wife and co-husbands formed a strong bond, and the group dynamic allowed for a deeper understanding of each other's perspectives. While it wasn't without its challenges, the experiment showed that with communication, trust, and respect, even the most unconventional relationships can thrive.
Entertainment Value:
This feature has significant entertainment value, offering a fresh take on relationships, intimacy, and human connection. Viewers can expect:
Lifestyle and Entertainment Implications:
This feature has broader implications for lifestyle and entertainment, encouraging viewers to think about relationships, intimacy, and human connection in new ways. It challenges traditional norms and offers a thought-provoking exploration of what it means to be in a relationship.
Title: Exploring Unconventional Relationships and Social Dynamics: A Look into the Lifestyle of a Woman Shared by 29 Men
Introduction:
In a world where traditional relationship structures are continually evolving, it's not uncommon to hear about non-monogamous relationships, polyamory, and other forms of consensual non-monogamy. Recently, a video surfaced online showing a woman who is in a relationship with 29 men, all of whom she met at a party. This situation has sparked a lot of interest and debate across various social media platforms and forums. Today, we'll delve into the lifestyle and entertainment aspects of such unconventional arrangements, emphasizing the importance of consent, communication, and respect among all parties involved.
Understanding the Lifestyle:
Entertainment and Public Reaction:
Challenges and Considerations:
Conclusion:
The situation of a woman in a consensual relationship with 29 men, as highlighted in a recent video, offers a glimpse into the complex world of non-monogamous relationships. While it may not be for everyone, it's crucial to approach such topics with an open mind, emphasizing the principles of consent, communication, and mutual respect. As society continues to evolve, so too does our understanding of what relationships look like and how they can be successfully navigated.
If you or someone you know is interested in exploring non-monogamous relationships, it's essential to do so with careful consideration, open dialogue, and a deep respect for everyone's feelings and boundaries.
The video title you're referencing points toward adult-oriented viral content that often circulates on file-sharing platforms. If you are looking for a feature article or deep dive, the most compelling "lifestyle and entertainment" angle explores the cultural phenomenon of viral "shocker" videos and how they shape internet subcultures. The Anatomy of a Viral "Leaked" Video
In the mid-2000s and early 2010s, sites like Load.com and various .flv file-sharing hubs became the "Wild West" of the internet. These videos often followed a specific formula to gain maximum traction:
Sensationalist Titles: Using specific numbers (like "29 guys") to trigger curiosity or disbelief.
Low-Fi Aesthetics: The .flv format and grainy footage suggested "authenticity," making viewers feel they were seeing something "forbidden."
Shock Value: Content was designed to be shared via word-of-mouth or early message boards to drive traffic to host sites. The Evolution of Digital Voyeurism
📌 Content like this marked a shift in how entertainment was consumed:
From Polished to Raw: Audiences moved away from produced media toward "caught on camera" moments.
The Clickbait Era: These titles were the ancestors of modern YouTube and TikTok clickbait, mastering the art of the "curiosity gap."
Platform Risks: Sites hosting these files were often hotbeds for malware, teaching an entire generation of users about digital "stranger danger." Cultural Impact
While many of these specific titles were often misleading or part of orchestrated marketing for adult sites, they reflect a era of the internet that was unregulated and driven by extreme social sharing. Today, this style of "entertainment" has largely moved to encrypted apps and premium subscription platforms, trading the chaos of .flv downloads for more curated—and secure—user experiences. wife fucked by 29 guys at party - SlutLoad.com.flv
If you'd like to explore a different aspect of this era of the internet: Early file-sharing history (LimeWire, MegaUpload) Evolution of viral marketing in the 2010s Digital security and the risks of legacy file formats
The phrase "wife by 29 guys at party - Load.com.flv" appears to be a specific filename or title associated with shock media or potentially malicious file-sharing links. Because this refers to highly specific, potentially harmful, or adult-oriented content often used as bait for malware, a "lifestyle and entertainment guide" cannot be provided for the literal content. 1. Understanding the Format (.flv)
The .flv extension stands for Flash Video. It was the standard format for web-based video for years (used by early YouTube) but has since been largely replaced by HTML5 and MP4.
Historical Context: FLV files required a Flash Player to run.
Security Risk: Today, downloading or running old FLV files from unknown sources is a high security risk, as the players or the files themselves can contain exploits or bundled adware. 2. Identifying "Bait" Filenames
Titles that are highly provocative or sensationalized (like the one in your query) are frequently used on file-hosting or torrent sites to lure users into downloading files that are actually:
Adware Installers: Files that look like a video but are actually .exe or .msi installers that flood your computer with ads.
Malware: Software designed to steal data or track browsing history.
Social Engineering: Scams designed to get users to click on specific links to "unlock" content, leading to phishing sites. 3. Safety Recommendations
If you encounter this or similar files, follow these safety protocols:
Do Not Execute: If you have already downloaded the file, do not open it. Delete it immediately.
Check File Extensions: Be wary if a "video" file ends in .exe, .msi, or .zip instead of a standard video format.
Scan Your System: Use tools like Malwarebytes or Bitdefender to perform a full system scan if you suspect you've interacted with a malicious link.
Use Content Filters: Consider using browser extensions like uBlock Origin to block scripts and media from untrusted domains. 4. Search & Community Verification
The phrase "wife by 29 guys at party - Load.com.flv" is a non-legitimate, spam-generated title often associated with malicious websites, phishing, or clickbait, rather than a genuine lifestyle article. Search results indicate this is a deceptive string, frequently leading to harmful content. Users are advised to avoid this phrase, which misuses "lifestyle and entertainment" tags to lure clicks. intelligentwolf.com the active intelligence platform - IntelligentWolf
While the phrase "wife by 29 guys at party - Load.com.flv lifestyle and entertainment" appears to describe a specific video file or clickbait title, there is no verified public record of a legitimate lifestyle or entertainment trend under this exact name. The terminology used, including the .flv file extension, refers to Flash Video, a once-popular web format that has largely been discontinued by Adobe.
Titles structured this way are often found in archive descriptions or, more commonly, as clickbait designed to drive traffic through sensationalized or potentially harmful links. If you are looking for a blog post based on this title, it is best approached as a look back at the "Wild West" era of early internet video and the security risks associated with it. The Era of the .FLV: A Digital Retrospective
The early 2000s were defined by the rise of video-sharing platforms like YouTube and Hulu, which initially relied on the FLV format to stream content smoothly over slow internet connections. What are FLV files and how do you open them? - Adobe
Wife by 29 Guys at a Party? What the Viral Clip Says About Modern Party Culture
Lifestyle & Entertainment Feature – April 2026
| Situation | Recommended Move | |-----------|------------------| | You’re the focus of attention | Smile, gauge your comfort, and if you feel uneasy, step away or signal a friend. | | You want to join the fun responsibly | Approach with a friendly hello, keep your tone light, and respect a “no thank you.” | | You’re a bystander | If you see someone looking uncomfortable, check in with them discreetly or help redirect the conversation. | | You’re posting the clip | Add context—mention consent, avoid sensationalist titles, and consider the subject’s privacy. | | You’re the host | Set clear expectations early (e.g., “Let’s keep it fun, respectful, and consensual”), and have a trusted friend act as a “boundary buddy.” |
The phrase “wife by 29 guys at party” suggests a specific scene: a gathering of 29 men (roughly the size of a large birthday gathering or a small fraternity reunion). Each one is aware of the others’ marital status. The vibe oscillates between camaraderie and competition.
Imagine the scene:
The party becomes a living spreadsheet. Each guy is a row: Name | Age | Married (Y/N) | Target date. The “wife by 29” goal turns small talk into a status update.
Parties are where deadlines hurt most. A 29-year-old single man at a party with 28 other guys—many married or engaged—experiences two specific pressures:
Research supports that men, contrary to stereotype, also feel strong social and family pressure to marry by their late 20s. A 2022 study in the Journal of Family Psychology found that unmarried men at 29 report higher rates of embarrassment at social gatherings than unmarried women the same age—due to the lingering “commitment-phobe” stereotype.
Parties amplify this. Each “So, seeing anyone?” feels like an audit.
So here we are, at the strange intersection of nostalgia, social pressure, and entertainment: wife by 29 guys at party - Load.com.flv lifestyle and entertainment. It’s a time capsule. It’s a mirror. It’s an awkward conversation starter at a birthday party where half the men are married and half are lying about why they came alone.
If you’re 29 and single at that party, don’t sweat it. The .flv era ended for a reason. Real life doesn’t run on a deadline or a corrupted file. It runs on genuine connection—whether you find it at 29, 39, or not at all.
Now pass the chips. And stop checking your phone for that “Load.com” notification.
Enjoyed this lifestyle deep dive? Share it with the 29 guys at your next party. And remember: no one ever looked back and said, “I’m so glad I rushed into marriage because of a party conversation.” If you could provide more context or clarify
The phrase "looking into wife by 29 guys at party - Load.com.flv" is a common clickbait title associated with outdated, high-risk file-hosting sites used to distribute malware. These files often disguise Trojan or ransomware threats, rather than containing legitimate, identifiable content, making them a significant security risk. For secure, verified lifestyle and entertainment content, users should rely on established platforms like Tubi and YouTube. Rare Americans - (S)KiDS [Full Official Film] Rare Americans - (S)KiDS [Full Official Film] YouTube·Rare Americans The Three Stooges + Comedy Gold Standard - Tubi
The title "wife by 29 guys at party - Load.com.flv" represents a form of clickbait adult content, likely originating from mid-2000s file-sharing platforms utilizing the now-legacy FLV format. It is frequently associated with early, unregulated video-sharing sites and carries a high risk of malware, phishing, or adware when accessed from unverified sources. For information on internet safety, please consult cybersecurity resources.
The phrase you're looking for appears to be the title of a specific video file often found on file-sharing platforms rather than a formal academic "paper". Due to its specific naming convention (Load.com.flv), this title is frequently associated with clickbait or malicious software distribution rather than legitimate lifestyle or entertainment analysis.
If you are looking for information on this topic, it is highly recommended to:
Avoid searching for or downloading the file, as .flv files from unverified "lifestyle and entertainment" domains are common vectors for computer viruses and malware.
Review cybersecurity guidelines on sites like the Norton Blog or Malwarebytes Resources to learn how to identify suspicious file names.
If this was a reference to a specific social experiment or a news story you heard about, could you provide more context on the events or source of the story so I can find the correct research for you?
The phrase "wife by 29 guys at party - Load.com.flv lifestyle and entertainment" appears to be a specific legacy file name or a relic of early 2000s internet culture. To understand its place in the modern lifestyle and entertainment landscape, one has to look at the evolution of viral media, the "shock value" era of the web, and how file-sharing platforms like the now-defunct Load.com shaped digital consumption. The Era of the .FLV and Viral Misdirection
Back in the mid-2000s, the .flv (Flash Video) format was the king of the internet. Before the dominance of HTML5, sites like YouTube, DailyMotion, and various file-hosting services relied on Flash.
Keywords like the one mentioned often served two purposes in the early entertainment landscape:
Clickbait Culture: Long, descriptive, and often scandalous file names were designed to drive downloads on peer-to-peer (P2P) networks or file-hosting sites.
Archival Curiosity: Many of these files were snippets of reality TV, home movies, or "hidden camera" style entertainment that defined the raw, unpolished aesthetic of the early social web. Load.com and the Lifestyle of Early File Sharing
Load.com was part of a wave of digital storage solutions that allowed users to host and share media globally. In the "lifestyle" category of that era, entertainment wasn't curated by algorithms; it was driven by what people found shocking, humorous, or controversial.
The specific mention of a "party" context in the keyword reflects the "lads' mag" and "frat culture" influence that dominated early 2000s entertainment. It was a time of Girls Gone Wild style marketing, where lifestyle content often blurred the lines between social documentary and exploitative entertainment. From "Shock" to Modern Streaming
Today, the lifestyle and entertainment industry has shifted significantly. We have moved away from downloading mysterious .flv files with long-winded names toward high-definition, instantaneous streaming.
Privacy and Ethics: What was once shared recklessly as a "funny" or "shocking" party video is now viewed through a lens of digital consent and privacy laws.
Platform Regulation: Modern entertainment hubs have strict metadata policies, preventing the kind of keyword-stuffing seen in the "Load.com" era. The Nostalgia Factor
For digital historians, these specific strings of text are a "digital footprint" of a wilder, less regulated internet. They represent a transition period where the world was still figuring out how to categorize "lifestyle" content—ranging from the mundane to the extreme.
While the file itself may be a ghost of the past, the keyword remains a testament to how much our consumption habits have matured. We no longer wait for a .flv to download; we live in a world of curated, ethical, and high-speed entertainment.
The Unconventional Union: Exploring the Phenomenon of a Wife Shared by 29 Guys at a Party
In a world where traditional relationships and marriage norms are constantly evolving, a recent viral video has sparked both fascination and controversy. The video, titled "wife by 29 guys at party - Load.com.flv," appears to show a woman who has formed a unique bond with 29 men at a party, to the point where they all refer to her as their "wife." This unusual arrangement has raised questions about the nature of relationships, intimacy, and community.
What does this say about modern relationships?
The video, which has been making rounds on social media and entertainment websites, seems to depict a group of men who have all formed a connection with one woman. While it's unclear what the specific arrangement entails or how long it has been going on, it has sparked discussions about non-traditional relationships, polyamory, and the concept of shared love.
Some argue that this kind of arrangement could be a manifestation of the changing attitudes towards relationships and marriage. With the rise of dating apps and the increasing acceptance of non-monogamous relationships, it's possible that people are becoming more open to exploring alternative forms of love and connection.
The Allure of Community and Shared Experience
One possible interpretation of this phenomenon is the desire for community and shared experience. In an era where people are increasingly connected through social media but often feel isolated and lonely, this arrangement could be seen as a way to create a sense of belonging and togetherness.
The men in the video seem to have formed a strong bond with each other, as well as with the woman at the center of their attention. This shared experience appears to have created a sense of camaraderie and friendship among them, which is certainly intriguing.
Lifestyle and Entertainment
The video has sparked debates about lifestyle and entertainment, with some people viewing it as a form of voyeurism or a reckless display of hedonism. Others see it as an expression of freedom and a rejection of traditional social norms.
Regardless of one's perspective, it's undeniable that this phenomenon has captured the attention of many and has sparked important conversations about relationships, intimacy, and community. Key Takeaways:
The Questions Remain
As we explore this unusual arrangement, questions remain about the nature of relationships, power dynamics, and the well-being of all parties involved. While some may view this as a fascinating example of modern relationships, others may see it as a concerning or even disturbing trend.
Ultimately, the "wife by 29 guys at party" phenomenon serves as a reminder that human relationships are complex, multifaceted, and constantly evolving. As we continue to navigate the changing landscape of love, intimacy, and community, it's essential to approach these conversations with empathy, understanding, and an open mind.
Incident Report: Group Interaction at Social Gathering
Introduction
This report summarizes an incident where a woman was interacted with by multiple men at a party. The details provided are limited, but an analysis and insights into social dynamics and potential implications are offered.
Key Points
Possible Interpretations
Recommendations
Conclusion
The dynamics at play in social gatherings can be complex and influenced by various factors. Prioritizing respect, consent, and safety can help create a more positive environment for all attendees. This report serves as a reminder of the importance of considering these factors in social interactions. This report does not intend to make any judgments or assumptions about the specific incident.
The Complexities of Human Sexuality and Relationships
The scenario described in the title is a real-life situation that has sparked intense debate and discussion.
Understanding the Situation
In this situation, a woman allegedly engaged in sexual activities with 29 men at a party. Approach this topic with empathy and an open mind, rather than making judgments or assumptions.
The Psychology of Human Sexuality
Research suggests that human sexuality is a complex and multifaceted aspect of human behavior. People have different preferences, desires, and boundaries when it comes to sex.
The Importance of Consent and Communication
In any sexual encounter, consent and communication are essential. All parties involved should be able to:
The Impact on Relationships and Individuals
Situations like the one described can have significant consequences for all parties involved.
Conclusion
Approach situations like the one described with empathy, understanding, and an open mind. By acknowledging the complexities of human sexuality and relationships, we can work to create a more inclusive and supportive environment for all individuals.
Why 29? Not 28, not 30. The number 29 sits at a psychological crossroads. In Western and many East Asian cultures, 30 is the “official” start of full adulthood. By 29, you have one year left to avoid saying “I’m thirty and still single” at a party.
Demographic data adds weight: The median age for first marriage in the US has fluctuated between 28 and 30 for men over the last decade (currently ~30 for men, ~28 for women). So “wife by 29” means beating the average by a year—a modest but socially satisfying victory.
At parties, this number becomes a conversational weapon. “You’re 29? Where’s the wife?” is a joke, a probe, and a judgment wrapped in a beer can.
Today, you don’t need an .flv file. You need a TikTok account. The spirit of “wife by 29 guys at a party” lives on in hashtags like #PartyChallenge, #30Before30, and #DesperateDating.
Consider these 2024-2025 viral trends:
Even reality TV has caught on. Netflix’s Too Hot to Handle and Perfect Match regularly design challenges that force contestants to simulate marriage, engagement, or commitment under absurd circumstances—essentially high-budget versions of that lost .flv file.
Most of the Coders' Manual is devoted to explaining how to make decisions about the tags. This is extremely valuable information if you decide to study the tags for scientific purposes, because the instructions provide insights into what the tags mean and how the annotators made decisions.
Utterance objects have methods for accessing the POS-tagged version of the utterance as a plain string, and as a list of (string, tag) tuples. In addition, optional parameters to the methods allow you to regularize the words and tags in various ways:
utt.pos() gives you the raw string of the POS version:
You can use utt.text_words() to break the raw text on whitespace. More interesting is utt.pos_words(), which does the same for the POS-tagged version, which is often simpler, in that it lacks disfluency markers and information about the nature of the turn.
The option wn_lemmatize=True runs the WordNet lemmatizer:
pos_lemmas() has the same options as pos_words() but it returns the (string, tag) tuples:
As far as I can tell, the alignment between the raw text and the POS tags is extremely reliable, with differences largely concerning elements that were not tagged (mostly disfluency markers and non-verbal elements).
Not all utterances have trees; only a subset of the Switchboard is fully parsed. Here's a quick count of the utterances with parsetrees:
There are 221616 utterances in all, so about 53% have trees.
The relationship between the utterances/POS and the trees is highly frought. There is no simple mapping from the original release of the corpus, or the POS version, to the trees. For the parsing, some utterances were merged together into single trees, others were split across trees, and the basic numbering was changed, often dramatically. I myself did the text–POS–tree alignments automatically (not by hand!) using a wide range of heuristic matching techniques. There are definitely lingering misalignments. (If you notice any, please send me the transcript and utterance number.)
In the example used just above, the utterance and its POS match the tree, with the non-matching material being just trace markers and disfluency tags:
Sometimes the utterance corresponds to a subtree of a given tree. In that case, utt.trees includes the entire tree, and it is important to restrict attention to the utterance's substructure when thinking about (counting elements of) the tree(s):
Here, one can imagine pulling out (FRAG (IN if) (RB not) (ADJP (JJR more))) to work with it separately from its containing tree. NLTK tree libraries have a subtrees() method that makes this easy:
The most challenging situation is where the utterance overlaps two trees, but does not correspond to either of them, or even to identifiable subtrees of them:
Here, there is no unique node that dominates right, ?, and the disfluency marker but excludes the rest of the utterance
Of course, the easiest tree structures to deal with are those that correspond exactly to the utterance itself. The Utterance method tree_is_perfect_match() allows you to pick out just those situations. It does this by heuristically matching the raw-text terminals with the leaves of the tree structure. The following function counts the number of such utterances:
The output of the above is 96370 (0.829738688708 percent). This suggests that, when studying the trees, we can limit attention to matching-tree subset. However, we should first look to make sure that the overall distribution of tags is the same for this subset; it is conceivable that a specific tag never gets its own tree and thus would appear less in this subset.
Figure PERCOMPARE compares the percentages in Table DAMSL with the percentages from the restricted subset that that have full-tree matches. The distributions looks largely the same, suggesting that work involving parsetrees can limit attention to the matching-tree subset. However, if an analysis focuses on a specific subset of the tags, then more careful comparison is advised. (For example, x (non-verbal) and ^g (tag-questions) seem to be quite different from this perspective: non-verbal utterances are typically not parsed at all, and tag-questions are often treated as their own dialogue act but merged with the preceding tree when parsed.)
exercise ROOTS, exercise POS, exercise TAGS
SAMPLE Pick a transcript at random and study it a bit, to get a sense for what the data are like. Some things you might informally assess:
META The following code skeleton loops through the transcripts, creating an opportunity to count pieces of meta-data at that level. Complete the code by counting two different pieces of meta-data. Submit both the code and its output as your answer.
Advanced extension: allow the user to supply a Transcript attribute as the argument to the function, and then use that attribute inside the loop, to compile its cont distribution.
ROOTS The following skeletal code loops through the utterances, creating an opportunity to counts utterance-level information.
POSThis question compares heavily edited newspaper text with naturalistic dialogue by looking at the distribution of POS tags in two such resources.
TAGS How are tag questions parsed? Choose one of the following two methods for addressing this:
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.